Ali K Esfahani
Diagonalization and Spectral Decomposition
As discussed earlier, eigenvalues and eigenvectors reveal the intrinsic structure of a linear transformation. Eigenvectors identify the natural directions of the system, and eigenvalues describe how the transformation acts along those directions. If we collect all eigenvectors of matrix A into a new matrix, we obtain a new coordinate system in which the matrix acts in the simplest possible way. This idea leads to diagonalization.
Let A ∈ ℝⁿˣⁿ be a square matrix with n linearly independent eigenvectors v₁, v₂, …, vₙ and corresponding eigenvalues λ₁, λ₂, …, λₙ. Let’s put all eigenvectors in a new matrix V:

Since for every eigenvector vᵢ we have Avᵢ=λᵢvᵢ, the multiplication of matrix A and matrix V can be written as

Where Λ is a diagonal matrix containing the eigenvalues:

If the full set of linearly independent eigenvectors for matrix A exists (i.e., Geometric Multiplicity (GM) = Algebraic Multiplicity (AM) for all eigenvalues), then, V is invertible and V ⁻¹ exists. So, we can write:

This expression is called the diagonalization of A.
Diagonalization means that there exists a coordinate system in which the transformation acts independently on each coordinate axis.
In the original basis, the matrix may rotate, stretch, and mix coordinates. But in the eigenvector basis, the transformation simply scales each coordinate direction by its eigenvalue. So, in this basis, everything becomes decoupled.
From now on, when we apply matrix A to a vector, we can interpret the mapping as a conceptual three-step process:

1. Change of basis to the eigenvector coordinates (y=V ⁻¹x),
2. Independent scaling along each eigen-direction (Λy),
3. Change of basis back to the original coordinates (VΛy = Ax).
For a dynamic system of equations, ẋ = Ax, diagonalization yields:

which means each mode evolves independently as:

This shows explicitly why eigenvalues control stability and transient behavior.
Similarly, in static systems, diagonalization reveals principal stiffness directions, principal stresses, or principal energy modes.
Note that, diagonalization is only possible as long as the full set of independent eigenvectors exists. This makes it clear why engineers are extremely interested in symmetric matrices: they always provide a complete set of independent eigenvectors. This is not accidental—it reflects the fact that symmetric transformations do not mix energy between orthogonal directions.
A general matrix does two things: it stretches space and it rotates/twists space. A symmetric matrix only stretches space along specific axes (the eigenvectors) and does not introduce rotational coupling between orthogonal directions. This means that motion or deformation along one eigenvector does not influence orthogonal directions. As a result, the principal stretching axes are perpendicular to each other. This remarkable property is formalized by the Spectral Theorem. We won’t go into the details, but it is essential to remember that any real symmetric matrix always has:
1. Real eigenvalues,
2. A complete set of orthonormal eigenvectors.
The second property is especially important. Symmetry not only ensures that the matrix V is invertible (by ensuring the availability of a full set of independent eigenvectors), but also the columns of V are orthogonal. In another word, for a symmetric matrix A, there always exists an orthogonal matrix Q and a real diagonal matrix Λ such that:
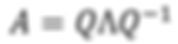
Where the columns of Q are orthonormal eigenvectors. Based on what we previously discussed about the properties of orthonormal matrices:

So, the decomposition of matrix A reduces to

This is called orthogonal diagonalization. Computationally, avoiding Q⁻¹ is a big achievement.
From a computational and theoretical perspective, avoiding the Q⁻¹ is a major advantage. Moreover, it also reveals that symmetric transformations can be understood as independent scaling along perpendicular directions. So, for computing A¹⁰, we don’t have to multiply A ten time. We just have to compute Λ¹⁰, which is by far an easier computation:

As already shown, diagonalization is a powerful tool, but it has an important limitation: it only applies to square matrices with a full set of eigenvectors. Many real engineering problems, however, involve rectangular matrices (including least-squares systems), where diagonalization is not defined.
This limitation motivates a more general and robust decomposition: Singular Value Decomposition (SVD). SVD generalizes diagonalization to any matrix, square or rectangular, symmetric or non-symmetric, and always exists. It will turn out that SVD is deeply connected to eigenvalues of AᵀA and AAᵀ. Just as orthogonal diagonalization showed that symmetric matrix act like pure scaling in an appropriate coordinate system, SVD will show that any matrix behaves similarly, but with two different orthogonal coordinate systems.
08